뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터






















 1
1


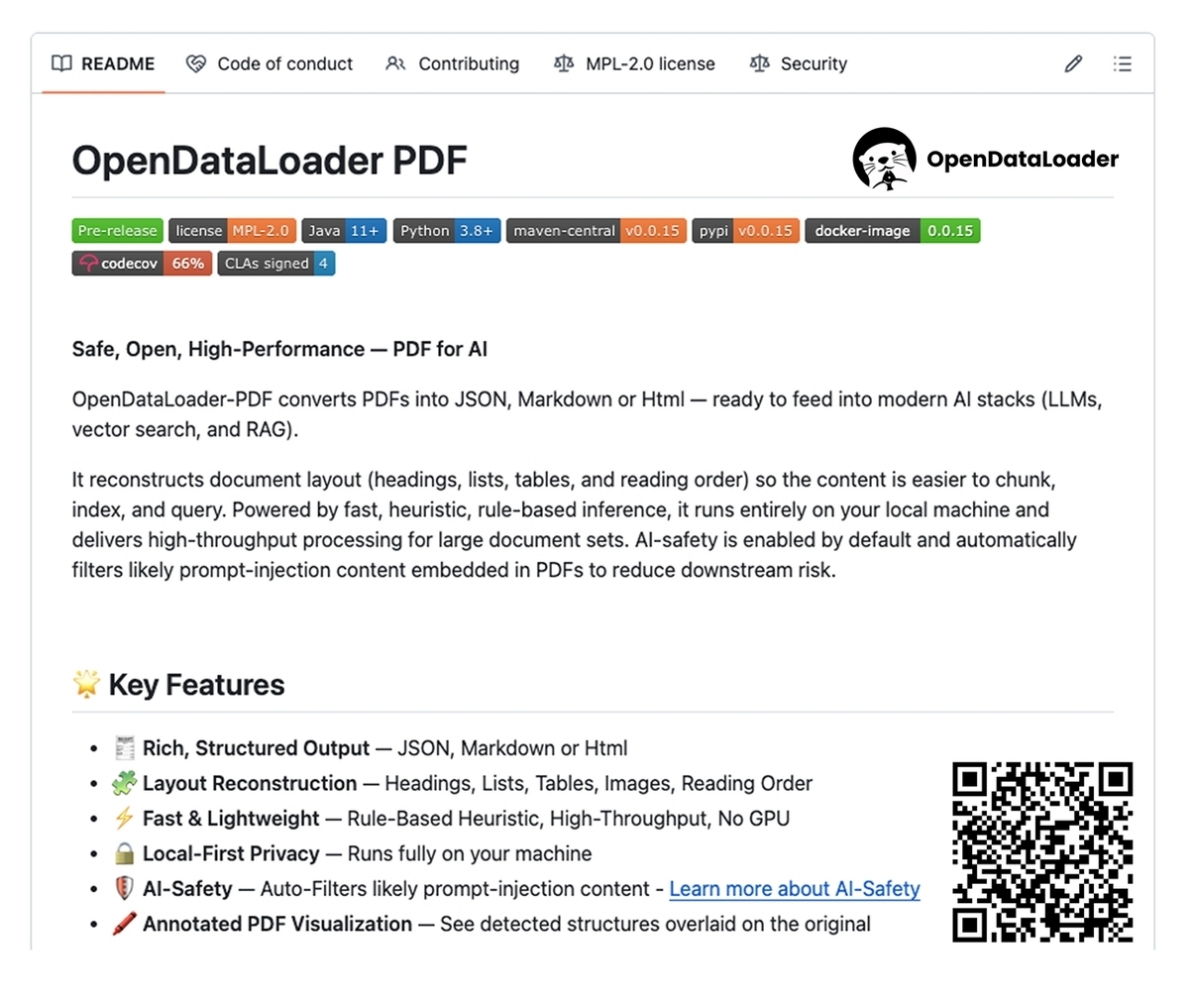
한글과컴퓨터가 인공지능(AI) 학습 과정에서 병목 현상으로 지목돼 온 PDF 문서 처리를 대폭 개선할 수 있는 기술을 자체 개발해 오픈소스로 공개했다. 이번 기술 공개는 AI 데이터 생태계 전반에 긍정적인 영향을 줄 수 있을 것으로 기대된다.
한글과컴퓨터는 9월 17일, 자사의 PDF 데이터 추출 기술인 ‘오픈데이터로더 PDF’를 누구나 활용할 수 있도록 오픈소스로 공개했다고 밝혔다. 이 기술은 PDF 문서에서 텍스트, 표, 이미지, 레이아웃 등의 정보를 정확하고 빠르게 추출해 AI 학습에 적합한 형태의 정형화된 데이터로 변환해주는 역할을 한다. 복잡한 구조 탓에 자동화가 쉽지 않았던 PDF 데이터 처리의 오랜 난제를 해소할 수 있는 도구라는 점에서 주목된다.
특히 한글과컴퓨터는 오픈데이터로더 PDF의 성능을 입증하는 지표로 NID(문서 내 정보의 인간 독서 순서를 정확히 복원하는 능력) 수치를 제시했다. 해당 기술은 기존 PDF 처리 솔루션 대비 NID 지표에서 85% 높은 성능을 기록한 것으로 알려졌다. 이는 기술이 실제 문서 배치와 논리 흐름을 얼마나 효과적으로 파악하는지를 보여주는 중요한 기준으로, 고품질 학습 데이터를 생성하기 위한 핵심 요소라고 볼 수 있다.
이번 기술 공개는 최근 허깅 스페이스(Hugging Space)가 선보인 방대한 AI 학습용 PDF 데이터셋 ‘파인PDFs(FinePDFs)’와 같은 움직임과도 맞물려 있다. 이 데이터셋은 4억7천500만 건에 달하는 문서로 구성돼 있으며, 이를 기반으로 한 학습을 원하는 기업이 늘어나고 있는 상황이다. 하지만 이처럼 대규모 PDF 데이터를 활용하려면 높은 정확도를 유지하는 문서 추출 기술이 필수적이기 때문에, 한컴의 기술이 시장 수요에 적기에 대응했다는 평가도 나온다.
한글과컴퓨터는 이번 기술을 캐나다 기반의 PDF 기술 전문 기업 듀얼랩과의 협업을 통해 공동 발전시켜 왔으며, 지난 7월 양사가 체결한 업무협약의 첫 결실이라고 설명했다. 앞으로는 보안을 강화하기 위한 기능도 추가할 예정이다. 예를 들어, 최근 문제로 떠오른 프롬프트 인젝션(인공지능에 악의적 명령을 삽입하는 공격 방식) 탐지 및 차단 기능 등을 적용해 기술의 신뢰성과 안전성을 높인다는 계획이다.
이 같은 기술 공개는 국내외 AI 기업들이 고속·고정밀의 문서 데이터 처리 도구를 손쉽게 활용할 수 있게 함으로써 AI 개발 효율성을 끌어올릴 것으로 기대된다. 앞으로 다양한 산업에서 AI 학습에 필요한 데이터 전처리 비용이 감소하면서, 관련 기술 상용화와 고도화를 가속화하는 계기가 될 가능성도 있다.





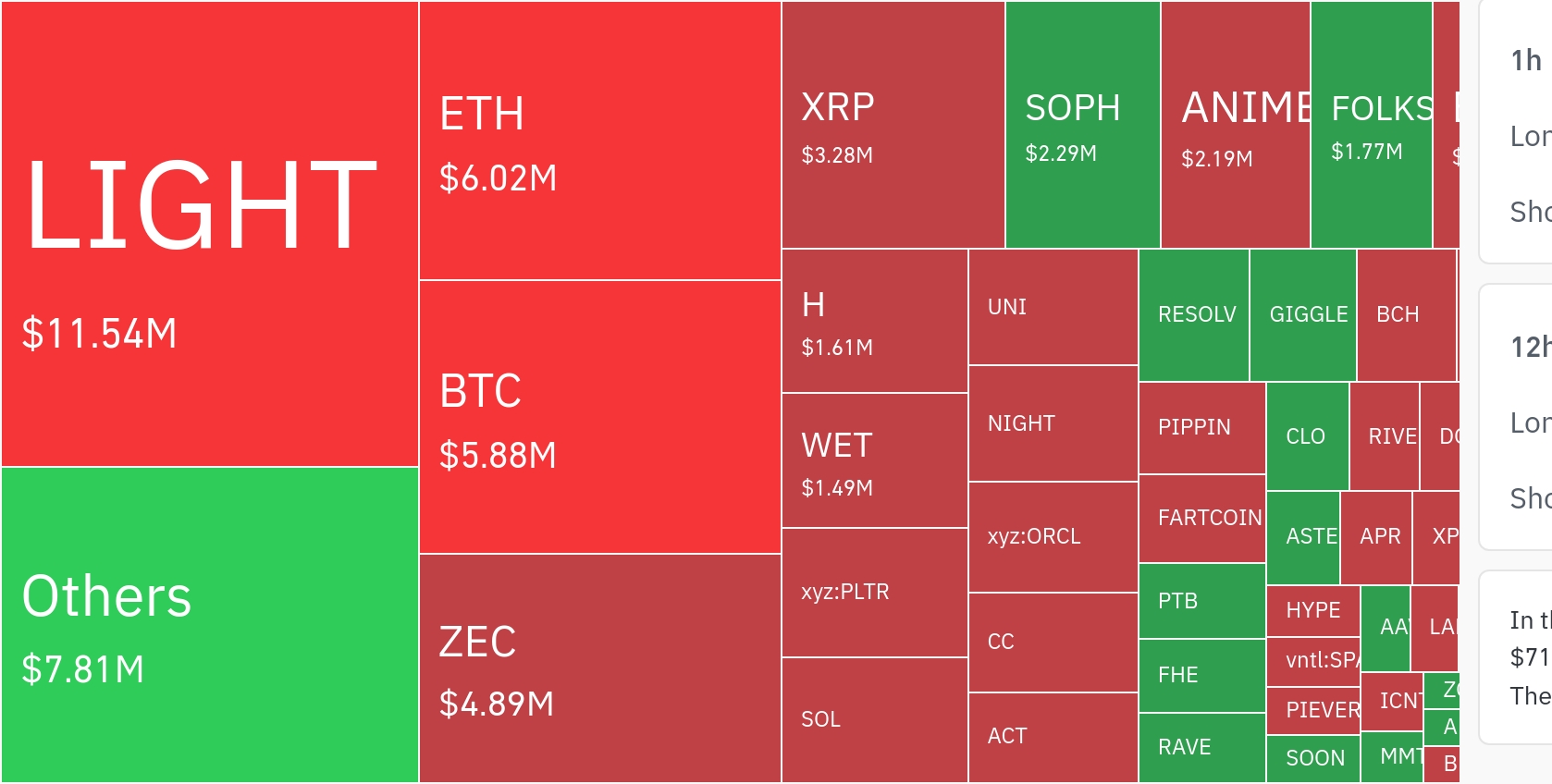

![[모닝 시세브리핑] 암호화폐 시장 혼조세… 비트코인 88,193달러, 이더리움 2,977달러](https://f1.tokenpost.kr/2025/12/rd81xd53pp.jpg)












![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd.png)
![[NOT코인] 기사퀴즈](https://f1.tokenpost.kr/2025/12/1be6hvu02x.png)
![[토큰포스트] 기사 퀴즈 495회차](https://f1.tokenpost.kr/2025/12/agr3wuw201.png)
![[토큰포스트] 기사 퀴즈 494회차](https://f1.tokenpost.kr/2025/12/5p4i9c3yxh.jpg)
![[토큰포스트] 기사 퀴즈 493회차](https://f1.tokenpost.kr/2025/12/lcyqi4iqyi.jpeg)