뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터






















 0
0



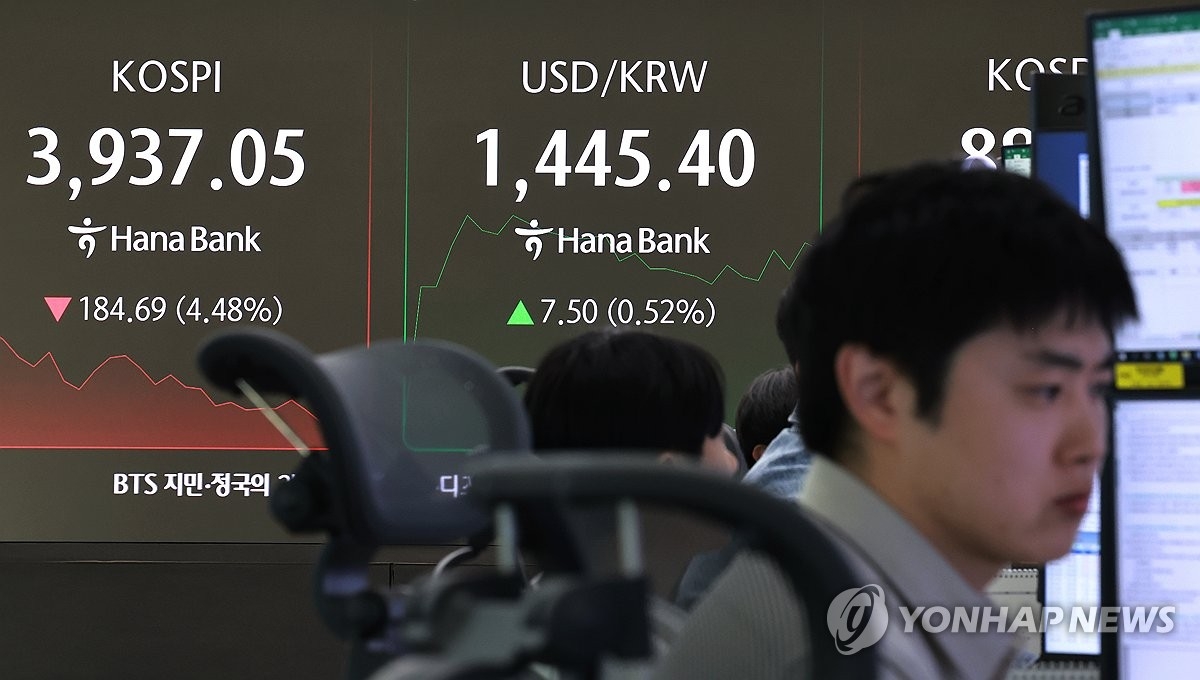
AI 팩토리의 주역으로 떠오른 엔비디아(NVDA)가 GPU를 넘어 네트워크 인프라 혁신에 집중하면서, 차세대 데이터센터의 기반을 다시 쓰고 있다. 인공지능 연산의 중심축이 개별 단일 GPU에서 전체 데이터센터로 확장되면서, 이를 하나의 슈퍼컴퓨터처럼 작동하게 만드는 핵심은 GPU 간을 연결하는 네트워크 인터커넥트 기술이다.
엔비디아의 마케팅 부문 수석부사장 길라드 샤이너(Gilad Shainer)는 최근 인터뷰에서 “AI 워크로드는 본질적으로 분산되어 있기 때문에, 수천 개 이상의 가속기를 하나의 계산 엔진처럼 작동시키는 정밀한 네트워크 조율이 필수적”이라고 강조했다. 지연 없이 동일한 데이터를 같은 속도로 각 GPU에 전달하는 구조가 구현되어야, 전체 연산 속도를 최적화할 수 있다는 설명이다.
이러한 분산처리 구조에서 네트워크는 단순한 연결 수단이 아닌, 실질적인 운영체제(OS)로 작동한다. 샤이너에 따르면, 개별 GPU 전용 ASIC(주문형 반도체)뿐 아니라 이들 가속기를 유기적으로 통합하는 네트워크 설계가 AI 팩토리의 성능을 결정짓는 가장 중요한 요소로 부상하고 있다.
엔비디아는 성능뿐 아니라 전력 효율성까지 고려해 네트워크를 하드웨어, 소프트웨어, 프레임워크 전반에 걸쳐 코디자인(Co-design) 방식으로 설계하고 있다. 모델 프레임워크부터 물리적인 연결까지 모든 컴퓨팅 요소가 통합적으로 설계될 때 비로소 토큰 처리 속도, 실행 효율, 예측성 등을 최대화할 수 있다고 샤이너는 강조했다.
특히 고밀도 설계는 엔비디아의 차별점이다. 기존 데이터센터가 과밀화를 꺼리는 경향이 강한 반면, 엔비디아는 고성능 GPU ASIC을 랙에 빽빽이 배치한 뒤, 전력 소모가 적은 동선(copper) 기반 연결을 통해 확장성과 에너지 효율을 모두 확보하는 전략을 택하고 있다. 대규모 확장 시에는 '스펙트럼-X 이더넷 포토닉스(Spectrum-X Ethernet Photonics)'나 '퀀텀-X 인피니밴드(Quantum-X InfiniBand)' 기술처럼 코패키지드 옵틱스(Co-packaged Optics)를 적용, 데이터 이동에 소요되는 에너지를 추가로 절감하고 있다.
이 같은 전략은 단순한 하드웨어 고도화를 넘어, 엔비디아가 AI 중심 컴퓨팅 시대에 ‘초대형 데이터센터 = 슈퍼컴퓨터’라는 새로운 패러다임을 구현하겠다는 야심을 뚜렷하게 보여준다. AI 팩토리의 인프라 주도권이 ‘GPU 제조력’이 아닌, 데이터센서 전체를 하나의 유기적 컴퓨팅 유닛으로 만드는 능력으로 이동하고 있다는 신호다. AI 붐의 다음 단계는 바로 이 네트워크 주도형 컴퓨팅 아키텍처에서 시작될 것으로 보인다.



![[크립토 인앤아웃] BTC서 3.5억 달러, XRP서 1.1억 달러 대량 유출](https://f1.tokenpost.kr/2025/11/wm53csqojk.png)
![[자정 뉴스브리핑] 블랙록 IBIT, $6.1억 비트코인 코인베이스 프라임으로 이체…추가 이체 가능성 外](https://f1.tokenpost.kr/2025/11/byq28ay6yr.jpg)













![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd.png)
![[Episode 6] 아트테크 하고, 에어드랍 받자!](https://f1.tokenpost.kr/2023/08/3b7hm5n6wf.jpg)
![[토큰포스트] 기사 퀴즈 474회차](https://f1.tokenpost.kr/2025/11/kkr71pp4vc.jpg)
![[토큰포스트] 기사 퀴즈 473회차](https://f1.tokenpost.kr/2025/11/0o9f6lahsw.jpg)
![[토큰포스트] 기사 퀴즈 472회차](https://f1.tokenpost.kr/2025/11/we5pg3atbe.jpg)
![[토큰포스트] 기사 퀴즈 471회차](https://f1.tokenpost.kr/2025/11/fum2h90w74.jpg)