뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터





















 1
1



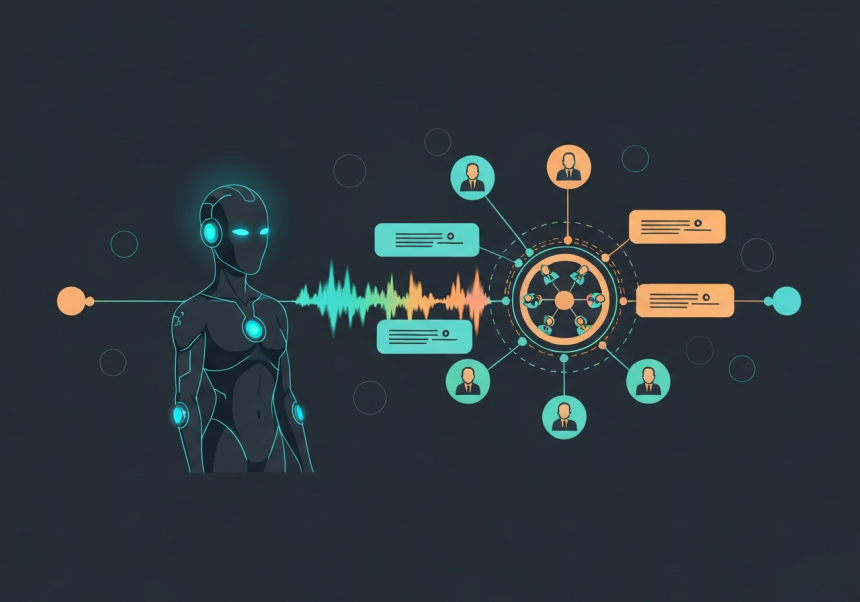
오픈AI 최고기술책임자(CTO) 출신 미라 무라티가 세운 씽킹머신즈랩이 사람과 AI 사이의 ‘끊기는 대화’를 줄이기 위한 새 모델 구조를 공개했다. 텍스트나 음성 입력이 끝날 때까지 기다렸다가 답하는 기존 방식에서 벗어나, 보고 듣고 말하는 작업을 동시에 처리하는 ‘실시간 상호작용’ AI를 내세운 점이 핵심이다.
씽킹머신즈랩은 최근 블로그를 통해 첫 ‘인터랙션 모델’ 연구 프리뷰를 발표했다. 이 모델은 기존 생성형 AI처럼 사용자가 질문을 모두 마칠 때까지 대기한 뒤 응답하는 구조가 아니라, 약 200밀리초(ms) 단위의 작은 구간으로 입력과 출력을 나눠 처리한다. 덕분에 AI가 말을 하는 도중에도 시각·청각 신호를 계속 받아들이고, 상황 변화에 즉각 반응할 수 있다고 회사 측은 설명했다.
현재 대다수 AI 서비스는 사용자가 문장을 끝내야 처리와 응답이 가능하다. 이 때문에 사람은 자연스럽게 끼어들거나 맞장구를 치는 대신, 이메일 쓰듯 질문을 길게 정리해 한 번에 던지는 방식에 익숙해졌다는 게 회사 측 판단이다. 씽킹머신즈랩은 이런 구조가 오히려 인간이 인터페이스에 자신을 맞추게 만든다고 보고, 보다 자연스러운 ‘실시간 상호작용’ 환경이 필요하다고 강조했다.
이번에 공개된 핵심 모델은 ‘TML-인터랙션-스몰’이다. 2760억 개 매개변수를 갖춘 전문가 혼합(Mixture-of-Experts) 모델로, 빠른 대화 흐름과 즉각적인 반응을 담당한다. 여기에 별도의 비동기식 ‘백그라운드 모델’이 붙어 복잡한 추론, 웹 검색, 도구 호출 같은 무거운 작업을 뒤에서 처리한다. 쉽게 말해 앞단 모델이 대화를 자연스럽게 이어가는 동안, 뒷단 모델이 필요한 정보와 계산을 준비해 결과를 실시간으로 대화에 녹여 넣는 구조다.
기술적으로는 오디오나 비디오를 별도 인코더로 무겁게 변환하는 대신, 가벼운 임베딩 계층을 통해 원시 신호를 직접 받아들이는 ‘인코더 프리 조기 융합’ 방식을 채택했다. 이를 통해 트랜스포머 내부에서 빠르게 처리해 지연 시간을 줄였다고 회사는 주장했다. 응답 속도와 깊은 추론을 동시에 잡기 위해 ‘듀얼 모델’ 구조를 설계했다는 설명이다.
성능 지표도 함께 공개됐다. AI 상호작용 품질을 측정하는 ‘FD-벤치’에서 TML-인터랙션-스몰의 턴테이킹 지연 시간은 0.4초 미만으로 집계됐다. 이는 구글의 제미나이-3.1-플래시-라이브 0.57초, GPT-리얼타임-2.0의 1.18초보다 빠른 수치다. 다만 이는 회사가 제시한 벤치마크 결과인 만큼, 실제 서비스 환경에서 같은 수준의 성능이 재현되는지는 추가 검증이 필요하다.
시장에서는 이런 저지연 AI가 단순한 ‘더 빠른 챗봇’을 넘어 기업용 현장에서 더 큰 의미를 가질 수 있다고 본다. 예를 들어 실험실이나 제조시설의 영상 피드를 상시 모니터링하면서 안전 위반 징후를 즉시 알리거나, 고객센터 통화에서 사람과 대화하듯 자연스럽게 응답하는 식이다. 시간 개념을 내부적으로 다룰 수 있어 “이번 화학 반응이 지난번보다 오래 걸리면 알려줘” 같은 지시도 별도 타임스탬프 없이 처리할 수 있다는 점도 눈에 띈다.
씽킹머신즈랩은 현재 TML-인터랙션-스몰과 백그라운드 모델을 일부 파트너에게만 제한적으로 제공하고 있다. 일반 공개는 올해 후반으로 예정됐다. 생성형 AI 경쟁이 ‘성능’에서 ‘상호작용 품질’로 옮겨가는 흐름 속에서, 이번 실시간 상호작용 모델이 차세대 AI 인터페이스의 방향을 가늠할 변수로 떠오르고 있다.




![[모닝 뉴스브리핑] 미국 비트코인 및 이더리움 ETF에서 대규모 자금 유출 外](https://f1.tokenpost.kr/2026/06/tl51iqavuk_th_860x0.webp)

![[모닝 시세브리핑] 암호화폐 시장 상승세… 비트코인 59,780달러, 이더리움 1,577달러](https://f1.tokenpost.kr/2026/06/gco1jpg0pv_th_860x0.webp)
![[토큰명언]](https://f1.tokenpost.kr/2026/06/121765d2t2_th_860x0.webp)
![[오후 뉴스브리핑] 미군, 이란 시설 공습 外](https://f1.tokenpost.kr/2026/06/ijf7t2n6uy_th_860x0.webp)

![[토큰운세] 2026년 6월 27일 띠별 토큰 운세](https://f1.tokenpost.kr/2026/06/lz4azuo834_th_860x0.webp)
![[마켓분석] 달러는 박스권인데 원화만 무너졌다](https://f1.tokenpost.kr/2026/06/c6emr3lelc_th_860x0.png)

![[온체인분석] 토큰화 자산의 78%는 '껍데기'였다 — 판테라가 드러낸 RWA의 불편한 진실](https://f1.tokenpost.kr/2026/06/6m1b948ry5_th_860x0.webp)






![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6_th_860x0.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6_th_860x0.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd_th_860x0.png)
![[Episode 6] 아트테크 하고, 에어드랍 받자!](https://f1.tokenpost.kr/2023/08/3b7hm5n6wf_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 625회차](https://f1.tokenpost.kr/2026/06/30m1n4oku9_th_860x0.png)
![[토큰포스트] 기사 퀴즈 624회차](https://f1.tokenpost.kr/2026/06/gqxz7npqa6_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 623회차](https://f1.tokenpost.kr/2026/06/3agy6d8gdf_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 622회차](https://f1.tokenpost.kr/2026/06/x6ct96x0hs_th_860x0.png)