






 뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터




















 5
5



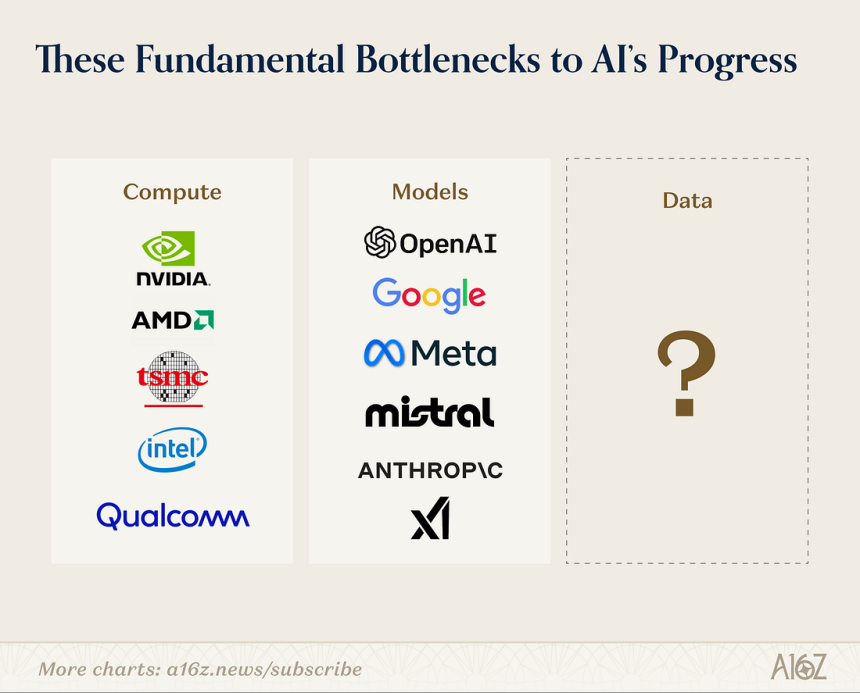
최근 인공지능(AI) 기술 경쟁에서 알고리즘과 반도체를 넘어 데이터 확보와 활용 능력이 핵심 변수로 떠오르고 있다.
11일(현지시간) 바비 새뮤얼스 프로테제 CEO는 a16z 포스트에서 AI 연구자들은 현재 AI 발전을 가로막는 가장 큰 병목이 데이터라고 지적했다.
그는 AI 발전의 핵심 요소가 알고리즘, 컴퓨팅, 데이터 세 가지이며 최근 몇 년 동안 알고리즘 연구와 컴퓨팅 인프라 확장은 빠르게 진행됐다고 설명했다.
오픈AI, 앤트로픽, 구글 딥마인드 등 연구소들이 알고리즘 발전을 이끌고 있고 엔비디아를 비롯한 반도체 기업들은 컴퓨팅 성능 경쟁을 벌이고 있지만 실제 모델을 학습시키는 고품질 데이터는 여전히 부족한 상태라고 짚었다.
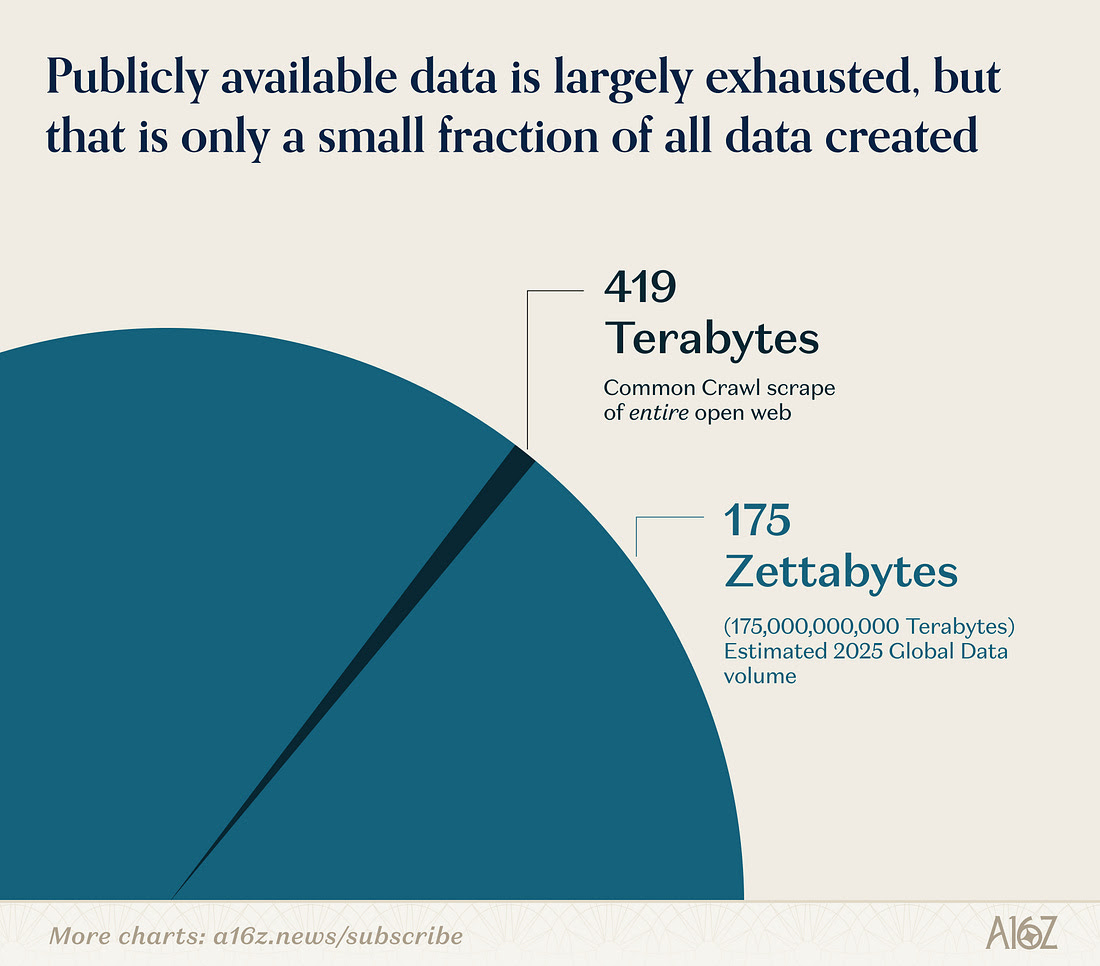
비영리 데이터 프로젝트 커먼크롤(Common Crawl)이 공개 웹에서 수집한 전체 데이터 규모는 약 419테라바이트(TB) 수준으로 나타났다.
반면 2025년 전 세계에서 생성될 것으로 추정되는 전체 데이터 규모는 약 175제타바이트(ZB)로, 이는 약 1750억 테라바이트에 해당한다. 즉 AI 모델이 주로 학습에 활용하는 공개 인터넷 데이터는 전 세계에서 생성되는 데이터의 극히 일부에 불과하다는 의미다.
이는 의료 기록, 기업 내부 데이터, 영상·음성 데이터, 산업 운영 데이터 등 대부분의 현실 세계 데이터가 여전히 비공개 영역에 존재한다는 점을 보여주며 향후 AI 발전은 이러한 실제 세계 데이터에 접근하고 이를 학습 데이터로 활용할 수 있는지 여부에 크게 좌우될 가능성이 크다는 점을 시사한다.
그는 AI 에이전트 시대가 본격화되면서 데이터의 중요성이 더욱 커지고 있다고 말했다.
프로테제 CEO는 "AI 에이전트가 실제 업무를 수행하려면 단순한 텍스트 데이터가 아니라 사람들의 실제 업무 흐름과 상호작용을 반영한 데이터가 필요하다"면서 "어떤 작업을 AI가 학습해야 하는지, 실제 산업에서 자동화 가치가 있는 업무가 무엇인지 분석하는 작업 자체가 새로운 연구 분야로 떠오르고 있다"고 덧붙였다.
아울러 현재 많은 데이터 기업들이 모델 평가나 인간 피드백 기반 강화학습(RLHF) 같은 제한적인 작업 중심으로 데이터를 생산하고 있다면서 "이러한 방식으로 생성된 데이터는 실제 인간 활동에서 발생하는 복잡한 맥락과 현실적인 의사결정 과정을 충분히 반영하지 못하는 한계가 있다"고 말했다.
그는 "앞으로 AI 발전을 위해서는 의료 기록, 음성 대화, 영상, 실제 업무 데이터 등 현실 세계에서 생성되는 다양한 데이터가 필요해질 것"이라면서 "데이터를 확보하고 구조화하며 AI 학습에 적합하게 가공하는 ‘AI 데이터 산업’이 새로운 핵심 분야로 성장할 가능성이 크다"고 설명했다.

![[특징주] HD현대중공업, 2분기 호실적에 AI 전력 인프라 기대까지…장초반 강세](https://f1.tokenpost.kr/2026/07/rs7kijtuzz_th_860x0.webp)





![[토큰운세] 2026년 7월 30일 띠별 토큰 운세](https://f1.tokenpost.kr/2026/07/v6pqibdnw5_th_860x0.webp)


![[토큰분석] “에이전틱 AI는 토큰화된 레일을 요구한다”… 자율 금융의 서막](https://f1.tokenpost.kr/2026/06/h0hajpmu3l_th_860x0.jpg)

![[토큰분석] 토큰화 세계의 세 갈래 길… 단일·공통·호환 원장이 가르는 ‘원자적 결제’의 운명](https://f1.tokenpost.kr/2026/07/lxapxeb99a_th_860x0.png)






![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6_th_860x0.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6_th_860x0.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd_th_860x0.png)
![[Episode 6] 아트테크 하고, 에어드랍 받자!](https://f1.tokenpost.kr/2023/08/3b7hm5n6wf_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 651회차](https://f1.tokenpost.kr/2026/07/1uxkqvlzy7_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 650회차](https://f1.tokenpost.kr/2026/07/349g53mba5_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 649회차](https://f1.tokenpost.kr/2026/07/ajg5n7xjmu_th_860x0.png)
![[토큰포스트] 기사 퀴즈 648회차](https://f1.tokenpost.kr/2026/07/aqswbnyids_th_860x0.webp)

![[토큰명언]](https://f1.tokenpost.kr/2026/07/n0ve5my4hz_th_860x0.jpg)


![[속보] 연준, 기준금리 3.50~3.75% 동결…3명 위원은 금리 인상 소수의견](https://f1.tokenpost.kr/2026/07/c7x38kaerm_th_860x0.png)


















