






 뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터




















 1
1



① 서울도 피해가지 못했다 — 삼성·하이닉스 동반 급락
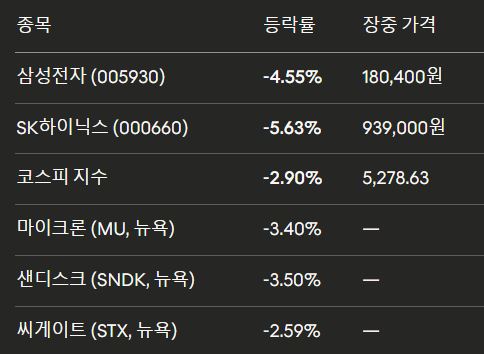
2026년 3월 26일, 충격은 월스트리트에서 끝나지 않았다. 서울 증시에서도 코스피 시가총액 1·2위인 삼성전자와 SK하이닉스가 동반 급락하며 지수 전체를 끌어내렸다.
오후 12시 23분 기준 코스피는 전 거래일 대비 163.58포인트(2.90%) 하락한 5278.63을 기록했다. SK하이닉스는 5만 6000원(5.63%) 내린 93만 9000원, 삼성전자는 8600원(4.55%) 떨어진 18만 400원을 나타냈다.
국내 증권가는 원인을 즉각 지목했다. 미래에셋증권 서상영 연구원은 "구글의 터보퀀트 발표 이후 데이터센터에 쓰이는 D램과 낸드 등 메모리 수요 둔화 우려가 커지며 마이크론 하락 여파가 이어졌다"며 "삼성전자와 SK하이닉스도 떨어지며 코스피 지수 하락을 주도했다"고 분석했다.
② 하루 만에 메모리 섹터를 강타한 'TurboQuant'
이 충격의 진원지는 구글 리서치가 전날(현지시간 3월 24일) 공개한 단 하나의 논문이었다. 'TurboQuant'라고 명명된 이 알고리즘은 대형 언어 모델(LLM) 및 벡터 검색 엔진에서 발생하는 추론(inference) 과정의 메모리 병목을 획기적으로 해소한다고 주장한다. 요점은 명확하다: AI 모델 메모리를 6배 압축하면서도 정확도 손실 없이, 동일한 GPU로 8배 빠른 속도를 달성한다는 것이다.
키움증권 한지영 연구원은 "터보퀀트 공개 이후 동일한 메모리로 6배 더 긴 대화를 처리할 수 있게 되면서 메모리가 생각보다 덜 필요한 것이 아닌가라는 부정적인 인식이 형성되고 있다"고 설명했다.
다만 그는 "어디까지나 논문 상 알고리즘 공개이고, 실제 상용화까지도 시간은 소요된다"며 "연초 메모리 폭등 랠리 피로도가 완전히 풀리지 않은 상황 속에서 추가적 차익실현의 명분으로 작용한 성격이 있지 않나 싶다" 고도 했다.
③ TurboQuant란 무엇인가 — 기술 해설
TurboQuant가 겨냥하는 것은 AI 모델의 '가중치(weights)'가 아니다. 대화가 진행되는 동안 모델이 처리해야 하는 중간 연산 결과를 저장하는 'KV 캐시(Key-Value Cache)'다. 컨텍스트 창이 수백만 토큰 규모로 확장되면서 이 KV 캐시는 세션당 수백 기가바이트에 달하는 GPU 메모리를 잠식해왔다. 이것이 지금까지 AI 추론의 진짜 병목이었다.
구글 리서치는 그 대안으로 'PolarQuant'를 제시했다. 데이터의 기하학적 구조를 단순화시키는 기술로, 소수점이 이어지는 숫자를 정수로 표시하는 것과 비슷하다. 정확도를 유지하기 위해서는 양자화된 존슨-린덴스트라우스 변환(QJL) 기법을 적용했다. 기존 데이터와 압축 데이터 간의 차이를 보존하되, 각 결과 벡터를 +1 또는 -1의 부호 비트로 표시해 메모리를 최소화했다.
구글은 이 기술을 오픈소스 AI 모델인 젬마(Gemma), 미스트랄(Mistral) 등의 연산에 적용한 결과, 데이터를 대부분 유지한 채 KV 캐시 용량을 6분의 1로 줄였다고 밝혔다. 4비트 TurboQuant를 통해서는 엔비디아의 H100 GPU 성능을 8배 높였다는 설명이다.
그리고 결정적인 차별점: DeepSeek의 효율성 개선이 모델 아키텍처를 처음부터 다시 설계해야 했던 것과 달리, TurboQuant는 재훈련이나 파인튜닝이 전혀 필요 없다. 기존 추론 파이프라인에 곧바로 삽입할 수 있다.
④ 커뮤니티의 검증 — "실제로 작동한다"
구글 리서치의 공식 발표는 엑스(X, 구 트위터)에서 770만 뷰를 돌파하며 폭발적 반응을 얻었다. 기술 분석가 @Prince_Canuma는 Apple 실리콘용 로컬 AI 라이브러리 MLX에 TurboQuant를 이식해 Qwen3.5-35B 모델을 직접 테스트했다. 컨텍스트 길이 8,500~64,000토큰 전 구간에서 양자화 수준과 무관하게 100% 정확히 일치하는 결과가 나왔다. 2.5비트 TurboQuant 적용 시 KV 캐시가 약 5배 줄었음에도 정확도 손실이 없었다.
"TurboQuant는 구글의 딥시크 모멘트다." — Cloudflare CEO 매튜 프린스 (Matthew Prince)
프린스 CEO는 "AI 추론 속도, 메모리 사용량, 전력 소비 등을 최적화할 여지가 훨씬 많아졌다"고 분석했다.
⑤ 시장 충격의 논리 — 왜 메모리 주식이 폭락했나
논리는 단순하고 냉혹하다. AI 추론에 필요한 메모리가 6분의 1로 줄어든다면, 그동안 AI 수요 급증을 근거로 메모리 공급을 억제해 가격을 끌어올린 삼성전자·SK하이닉스·마이크론 등의 수익 전망에 직격탄이 된다.
지난 10월 이후 AI 추론의 메모리 병목이 부각되면서 DDR 가격이 3개월 만에 최대 7배나 급등했다. 이른바 '메모리 카르텔'이라 불리기도 하는 과점적 공급 구조 하에서, 주요 업체들은 수요를 핑계로 2027년 이전까지 신규 공급 확대를 미루겠다는 입장이었다.
그런데 TurboQuant가 등장하자 방정식이 바뀌었다. AI 기업들은 이미 보유한 GPU에서 소프트웨어만으로 훨씬 적은 메모리를 사용할 수 있다. 더 중요한 것은 '이제 시작'이라는 점이다. 구글이 이 정도 효율을 달성했다면, 추가 최적화와 경쟁 알고리즘의 등장으로 효율은 더욱 높아질 것이 거의 확실하다.
⑥ 한국 증시·코스피에 대한 함의
코스피에서 삼성전자와 SK하이닉스가 차지하는 비중을 감안할 때, 메모리 수요 내러티브가 무너질 경우 한국 증시 전체가 직격을 받을 수 있다. 두 회사의 '메모리 수요 프리미엄'이 사라질 경우 코스피가 현재 대비 최대 100% 과대평가 상태일 수 있다는 극단적 시나리오까지 거론된다.
그러나 ICLR 2026에서 논문이 정식 발표되기도 전에, 커뮤니티는 MLX·llama.cpp에 구현을 완료했고 실제 검증 결과를 쏟아내고 있다. 시장은 상용화를 기다리지 않는다 — 가능성 자체에 이미 반응했다.
⑦ 토큰포스트 시각 — AI는 '더 많은 칩'에서 '더 나은 메모리'로
TurboQuant의 등장은 AI 효율화 경쟁의 축이 이동하고 있음을 보여준다. DeepSeek이 훈련 비용 측면의 패러다임을 흔들었다면, TurboQuant는 추론 단계의 메모리 구조를 흔들고 있다. 두 사건의 공통 메시지는 하나다: 하드웨어를 더 사지 않아도 된다.
물론 한계는 명확하다. KV 캐시에만 적용되며 모델 가중치는 건드리지 않고, 수십억 요청을 처리하는 실제 프로덕션 환경에서의 성능은 아직 검증되지 않았다. 그러나 재훈련 없이 기존 인프라에 즉각 적용 가능하다는 특성은 채택 장벽을 최소화한다.
AI 발전의 한계는 칩에 트랜지스터를 얼마나 집적하느냐가 아니라, 정보의 무한한 복잡성을 디지털 비트의 유한한 공간으로 얼마나 우아하게 변환하느냐에 있는 것 아닐까.






![[알트 현물 ETF] XRP 홀로 순유입...시장 관망 기류 확산](https://f1.tokenpost.kr/2026/06/mydi0kfyhu_th_860x0.webp)



![[마켓분석] “비트코인 머니마켓”이라더니… STRC는 비트코인 담보가 아닌 정크등급 신용상품이었다](https://f1.tokenpost.kr/2026/06/o9irm4g40b_th_860x0.png)
![[온체인분석] 토요일 새벽에 삼성전자를 산다 — '주식 Perp'의 정체](https://f1.tokenpost.kr/2026/06/v9im69r316_th_860x0.png)
![[온체인분석] 토큰화 자산의 78%는 '껍데기'였다 — 판테라가 드러낸 RWA의 불편한 진실](https://f1.tokenpost.kr/2026/06/6m1b948ry5_th_860x0.webp)






![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6_th_860x0.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6_th_860x0.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd_th_860x0.png)
![[Episode 6] 아트테크 하고, 에어드랍 받자!](https://f1.tokenpost.kr/2023/08/3b7hm5n6wf_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 624회차](https://f1.tokenpost.kr/2026/06/gqxz7npqa6_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 623회차](https://f1.tokenpost.kr/2026/06/3agy6d8gdf_th_860x0.webp)
![[토큰포스트] 기사 퀴즈 622회차](https://f1.tokenpost.kr/2026/06/x6ct96x0hs_th_860x0.png)
![[토큰포스트] 기사 퀴즈 621회차](https://f1.tokenpost.kr/2026/06/mo6k0enswp_th_860x0.png)














![[특징주] 썸에이지, 10대 1 무상감자 뒤 거래 재개 첫날 급락](https://f1.tokenpost.kr/2026/06/wm1clue84m_th_860x0.jpg)












